오늘 소개할 논문은 Yu. et al의 2022년 연구인 "PhysFormer: Facial Video-Based Physiological Measurement with Temporal Difference Transformer" 입니다. 이 논문은 기존 CNN 기반 딥러닝 방식의 한계를 넘어, 장거리 시공간(spatio-temporal) 관계를 효과적으로 학습하는 Video Transformer 구조를 도입하여, 더욱 정밀하고 일반화 가능한 비접촉식 생체신호 추정을 실현한 최신 연구입니다.
CVPR 2022 Open Access Repository
PhysFormer: Facial Video-Based Physiological Measurement With Temporal Difference Transformer Zitong Yu, Yuming Shen, Jingang Shi, Hengshuang Zhao, Philip H.S. Torr, Guoying Zhao; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogn
openaccess.thecvf.com
GitHub - ZitongYu/PhysFormer: PhysFormer CVPR2022
PhysFormer CVPR2022. Contribute to ZitongYu/PhysFormer development by creating an account on GitHub.
github.com
🎯 연구의 동기
- 기존 rPPG 기반 심박 추정 모델들은 대부분 CNN 기반 구조를 사용했지만, 다음과 같은 문제점이 있었습니다:
- CNN의 receptive field가 좁아 장기적인 시공간 의존성(long-range spatio-temporal dependencies) 파악이 어려움
- 복잡한 움직임, 조명 변화, 표정 등 현실적 영상 조건에서 정확도가 크게 떨어짐
- 대부분 preprocessing이 복잡하거나 non-end-to-end 구조임
- 이러한 한계를 해결하기 위해 PhysFormer는 Transformer 기반의 구조를 도입하여, 얼굴 영상으로부터 심박수, 호흡수, 심박변이도(HRV)를 end-to-end로 추정합니다.
🧬 모델 구성: PhysFormer

- 구조 요약
- PhysFormer는 다음과 같은 네 부분으로 구성됩니다:
- Shallow Stem: 3개의 3D convolution layer로 입력 영상의 저수준 시공간 특징 추출
- Tube Tokenizer: 입력 시퀀스를 Tube 형태의 시공간 토큰으로 변환
- Temporal Difference Transformer Blocks (TD-Transformer):
- TD-MHSA: Temporal Difference 기반 Multi-head Attention
- ST-FF: Spatio-temporal Feed-Forward layer
- Predictor Head: 최종 rPPG 1D 파형 예측
- PhysFormer는 다음과 같은 네 부분으로 구성됩니다:
- 핵심 모듈
- Temporal Difference Multi-head Self Attention (TD-MHSA)
- 일반적인 self-attention 대신, Temporal Difference Convolution(TDC)을 통해 시간 축 변화 정보를 반영
- 미세한 색상 변화 (혈류 변화) 감지를 강화
- Spatio-temporal Feed-Forward (ST-FF)
- 일반 FFN 대신, Depthwise 3D Conv + Linear Layer를 사용하여 지역 정보 보완
- Temporal Difference Multi-head Self Attention (TD-MHSA)
📚 정교한 학습 전략
- Label Distribution Learning
- HR을 단일값(label)로 학습하지 않고, Gaussian 분포로 주변값까지 함께 학습하여 범주 간 유사성 반영
- Curriculum Learning 기반 Dynamic Loss
- 초기엔 시간 영역 손실(Temporal Loss) 위주로 학습, 이후 주파수 도메인 손실(Frequency Loss)을 점차 강화하여 과적합 방지 + 주기성 학습 강화
- $L_{total}=\alpha \cdot L_{time}+\beta \cdot (L_{CE}+L_{LD})$
- $\alpha$는 고정, $\beta$는 epoch 증가에 따라 지수적으로 증가
🧪 실험 결과 요약
- 사용된 데이터셋
- VIPL-HR: 고난이도 조명/움직임 포함 대규모 데이터
- MAHNOB-HCI: 다양한 감정 및 저조도 환경
- MMSE-HR: 감정 유발 기반 자연스러운 영상
- OBF: 고품질, 고해상도 rPPG/HRV/호흡 측정 가능
- 심박수(HR) 예측 정확도 (VIPL-HR 기준)

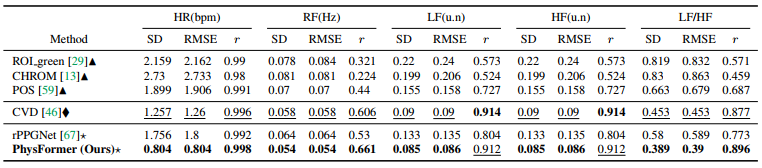
- 호흡수(RF) 및 심박변이도(HRV) (OBF 기준)
🔍 시각화 결과
- TD-MHSA의 attention map은 이마, 볼 등 혈류 변화가 뚜렷한 부위에 집중
- Query-Key attention의 응답이 rPPG 파형의 주기적 위치와 정확히 일치
- long-range attention을 통해 다양한 시간 구간 간 유사성 학습 가능

✅ 핵심 기여 정리
| 기여 요소 | 설명 |
| 장거리 시공간 학습 | TD-Transformer 구조를 통해 quasi-periodic 신호 학습 강화 |
| 정밀 예측 | HR, RF, HRV 모두 높은 정확도 유지 |
| 학습 최적화 | label distribution + dynamic curriculum으로 안정적 학습 유도 |
| 사전학습 불필요 | ImageNet 같은 대규모 사전학습 없이도 학습 가능 |
| 일반화 성능 | cross-dataset 테스트에서도 강한 성능 유지 (MMSE-HR 등) |
📝 마무리
- PhysFormer는 Transformer 기반 rPPG 심박수/호흡수 예측의 새로운 기준점을 제시한 논문입니다.
- CNN 기반 모델들이 처리하지 못하던 시공간 장거리 관계 학습을 성공적으로 구현했으며,
- 단순 HR 추정이 아닌 rPPG 파형 복원 + 주파수 기반 정밀 분석까지 가능하게 만들었습니다.