반응형
이번 논문에서는 생성형 모델의 시초라고 할 수 있는 Ho. et al.의 2020년 연구인 "Denoising Diffusion Probabilistic Models"을 소개 하려고 합니다. 이 논문은 오늘날 매우 주목받고 있는 Diffusion 모델의 출발점 중 하나입니다. 기존의 GAN, VAE와는 다른 방식으로 이미지를 생성하며, 놀라운 이미지 품질을 보여줍니다. Stable Diffusion, DALL·E 2 같은 모델들의 기반이 되는 개념이 바로 이 논문에서 시작되었습니다.
- Paper: https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
- Code: https://github.com/lucidrains/denoising-diffusion-pytorch
GitHub - lucidrains/denoising-diffusion-pytorch: Implementation of Denoising Diffusion Probabilistic Model in Pytorch
Implementation of Denoising Diffusion Probabilistic Model in Pytorch - lucidrains/denoising-diffusion-pytorch
github.com
🎯 Diffusion 모델이란?
- 아이디어 요약
- 원래 이미지를 조금씩 노이즈 추가해서 점점 흐리게 만듭니다. (→ Forward process)
- 흐릿해진 이미지에서 다시 원래 이미지를 복원하도록 학습합니다. (→ Reverse process)
- 즉, "사진을 망가뜨리는 과정을 정의한 다음", 이 과정을 거꾸로 되돌리는 능력을 학습하는 것입니다.
- 두 개의 과정
- Forward Process ($q$): 깨끗한 이미지에 점점 노이즈를 추가 (확률적으로 정의된 정방향 마르코프 체인)
- Reverse Process ($p_{\theta}$): 노이즈 이미지를 조금씩 깨끗하게 만들도록 신경망이 예측 (학습 대상)

🧠 수학 없이 이해하는 핵심 구조
| 단계 | 설명 |
| 1. 학습 이미지 선택 | 예: 고양이 사진 하나 선택 |
| 2. 노이즈 추가 | 반복적 랜덤 노이즈 추가해서 $x_0$ → $x_1$ → $ \ldots$ → $x_T$ |
| 3. 복원 학습 | $x_T$에서 $x_{T-1}$를 예측 → 반복하여 $x_0$ 복원하도록 학습 |
| 4. 새로운 샘플 생성 | $x_T$를 랜덤 노이즈로 설정 한 후, 학습된 복원 과정을 따라 새로운 이미지 생성 |
💡 핵심 기술:
- ε-예측 (Noise Prediction)
- 논문에서 제안된 가장 중요한 아이디어 중 하나는 노이즈 자체(ε)를 예측하도록 학습시키자!
- 이 방식은 아래와 같은 장점이 있습니다:
- 수학적으로 간단해집니다.
- 실제 이미지 품질이 매우 좋아집니다.
- 다른 모델들(GAN 등)보다 훈련 안정성이 높습니다.
- 이 구조는 오늘날 많은 Diffusion 기반 모델들이 채택한 표준입니다.
- 훈련 방식
- 논문에서는 간단한 손실 함수를 사용해 효율적인 학습을 도입합니다:
- $L_{\text{simple}}(\theta) = \mathbb{E}_{t, x_0, \epsilon} \left[ \left\| \epsilon - \epsilon_\theta\left( \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, t \right) \right\|^2 \right]$
- 여기서 각 기호는 다음을 의미합니다:
- $x_0$: 원본 이미지
- $\epsilon \sim \mathcal{N}(0, I)$: 표준 정규분포에서 샘플링한 노이즈
- $t \sim \text{Uniform}(\{1, \ldots, T\})$: 시간 단계
- $\bar{\alpha}_t = \prod_{s=1}^{t} \alpha_s = \prod_{s=1}^{t} (1 - \beta_s)$: 누적 감쇠 계수
- $\epsilon_\theta(x_t, t)$: 입력 $x_t$ 에 대해 노이즈를 예측하는 신경망
- 즉, 신경망이 "어떤 노이즈가 섞였는지"를 예측하도록 학습합니다. $x_t$는 $x_0$에 노이즈가 $t$단계 섞인 이미지이고, $ε$은 실제 노이즈입니다.
- 논문에서는 간단한 손실 함수를 사용해 효율적인 학습을 도입합니다:
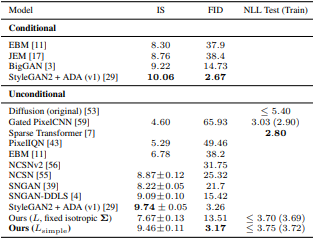
📊 성능 평가
- CIFAR-10 이미지 생성 기준:
- Inception Score (IS): 9.46 (당시 최고 수준)
- FID Score: 3.17 (낮을수록 좋음 → 매우 우수한 품질)
- 특히, GAN 모델들이 안정성 문제를 겪는 반면, DDPM은 안정적 훈련이 가능합니다.

✅ 결론 및 요약
| 항목 | 요약 |
| 핵심 아이디어 | 데이터를 점점 흐리게 만들고, 그 반대 과정을 학습 |
| 주요 기여 | ε-예측 기반 reverse process / 간단한 손실 함수 |
| 성능 | 이미지 품질 매우 우수 (GAN보다 나은 경우도 있음) |
| 영향력 | 다양한 현대 생성 모델의 기반이 된 중요한 연구 |
- 이 논문 이후로 Diffusion 기반 생성 모델은 다음과 같은 진화를 겪습니다:
- Latent Diffusion (속도 개선)
- Conditional Diffusion (텍스트-이미지 변환 등)
- Video, Audio 등 다양한 분야로 확장
📝 마무리
- 이 논문은 단순하지만 강력한 아이디어로 시작해, 오늘날의 고품질 이미지 생성 모델의 문을 열었습니다. 앞으로 다른 확장된 Diffusion 모델 논문들(Stable Diffusion, Latent Diffusion 등)도 함께 리뷰해 보도록 하겠습니다.
반응형